Ocaml and multicore programming
- by Gerd Stolpmann,
2011-05-07
Netmulticore is a part of Ocamlnet, and because the camlcity.org software
is also developed with Ocamlnet, it was quite natural and simple to use
this shared memory interface.
But let's step back first and look at the special problem that was solved.
Camlcity.org is not a simple web server - it is a cascade of a front-end
server and several back-end servers. The front-end is, more or less,
mixing the data coming from the back-ends, and transforms the data to
a presentable form using a template engine. The back-ends are also
HTTP servers. This is shown in this picture:
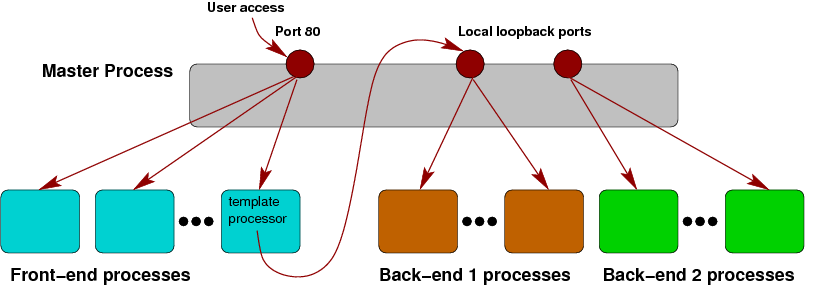
The nice aspect about this architecture is that the back-ends can be
individually deployed, and can run on different machines than the
front-end.
So, for example, if you view this blog post on camlcity.org, the text
of the blog article comes from a back-end server, and the front-end
creates the frame with the navigation elements. If you view this
blog with an RSS reader, the front-end just wraps the back-end text
differently so an RSS file is generated instead of a web page.
This architecture creates a little performance problem, though: For
processing a user request quite a number of accesses to the back-end
servers are required. Not only the article text needs to be fetched,
but also the required templates, and for generating the navigation
elements, also some neighbor texts (parents and siblings) need to be
requested from the back-ends. This can add up to a dozen or more
requests, and was the reason why using camlcity.org often felt a bit
sluggish.
Note that only use multi-processing is used: There is a master
process starting as many worker processes as needed (the workers
can be of different type, here front-ends or back-ends). The workers
can run in parallel, and even take advantage of several processor
cores. Also, the workers are fully separated from each other, so that
a malfunction (including crash) of one worker does not affect other
workers. A good feature for a software running 24/7.
However, multi-processing makes it difficult to share data between
workers. The workers have only their own process-local memory, and
cannot normally not make data available to others. Well, Netmulticore
changes the game at this point.
The improved architecture introduces a cache on the front-end
side. This cache stores all back-end responses where it is suspected
they could be requested soon again:
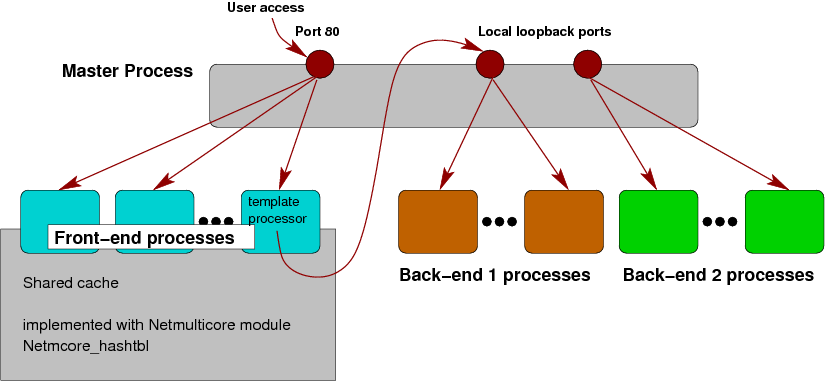
This cache resides in explicitly allocated shared memory (using the
POSIX interface shm_open). The Netmulticore library is
used to manage this block of shared memory. Besides other data
structures there is also Netmcore_hashtbl, an adaption of
the well-known Hashtbl module of the standard library for
use in shared memory.
As this code is really short and nice, I just show it here:
type cache_obj =
[ `Fields of Json_type.t * string option
| `Refs of Json_type.t
| `Html of Nethtml.document list
]
type cache_hdr =
{ mutable lock : Netmcore_mutex.mutex;
mutable next_gc : float
}
type cache =
(string, float * string * string * cache_obj, cache_hdr) Netmcore_hashtbl.t)
The values
cache_obj are stored in the cache (payload data).
As you see, we cannot only store strings, but structured Ocaml values
(with limitations, though). The shared hashtable features a so-called
header which exists once per hashtable. Here,
cache_hdr
includes a mutex (to ensure that only one process can write at a time),
and the field
next_gc which is the point in time when the
hashtable will be checked next for elements exceeding their lifetime.
The
cache, finally, maps URLs (given as strings) to tuples
(timeout, path1, path2, url,
element). Here,
timeout is the point in time when
the elements needs to be evicted from the cache, and the paths and URL
are further metadata.
The cache lookup is as easy as:
let cache_lookup path =
let cache = get_cache() in
let (t_out, real_path, real_url, obj) = Netmcore_hashtbl.find_c cache path in
if Unix.time() >= t_out then raise Not_found;
(real_path, real_url, obj)
Note that we leave out here
get_cache because it involves a
bit of application-specific management code.
The function Netmcore_hashtbl.find_c creates a copy of the
values found in the shared cache. This is required because we cannot allow
that pointers to shared values escape the scope of this module - such
pointers need special treatment (there are some programming rules to be
followed). The copy is put into normal process-local memory, so these
rules no longer apply then.
For storing value in the cache we have:
let cache_store path real_path real_url obj =
try
let cache = get_cache() in
let now = Unix.time() in
let t_out = now +. float !cache_default_timeout in
let hdr = Netmcore_hashtbl.header cache in
Netmcore_mutex.lock hdr.lock;
( try
if now >= hdr.next_gc then (
let l = ref [] in
Netmcore_hashtbl.iter
(fun p (t,_,_,_) ->
(* Warning: p, t are in shared mem *)
if now >= t then l := p :: !l
)
cache;
List.iter
(fun p ->
(* Warning: p is in shared mem *)
Netmcore_hashtbl.remove cache p
)
!l;
(* Floats are boxed! *)
Netmcore_heap.modify
(Netmcore_hashtbl.heap cache)
(fun mut ->
hdr.next_gc <- Netmcore_heap.add mut t_out
);
);
if Netmcore_hashtbl.length cache < !cache_limit then
Netmcore_hashtbl.replace
cache path (t_out, real_path, real_url, obj);
Netmcore_mutex.unlock hdr.lock;
with
| error ->
Netmcore_mutex.unlock hdr.lock;
raise error
)
with
| Netmcore_mempool.Out_of_pool_memory ->
Netlog.logf `Warning "Shared cache: Out of pool memory"
We use a lock to ensure that only one process can write at a time.
This lock is managed with Netmulticore's Netmcore_mutex
module. Essentially, the lock guarantees that all modifications done
at write time are done atomically, and thus consistency is preserved.
As you see we now and then throw out all elements exceeding their
lifetime. This is done (for simplicity) by iterating over the whole
hashtable, and checking each element. The keys of the found elements
are gathered up in l, and are removed in a second step.
Note that the iteration gives us direct pointers to shared memory, e.g.
p is a string residing in shared memory. One has to be
very careful with such values, because Netmulticore provides less
guarantees how long such values exist than Ocaml programmers are used
to. For example, once a key p is removed from the table,
the string counts as no longer referenced, and can be deleted by
Netmulticore's internal memory manager - even if we still have
the p variable (because Netmulticore cannot cooperate
with Ocaml's memory manager for this purpose).
Another strange thing is the Netmcore_heap.modify
function. It is required for modifying shared values in-place,
here next_gc. The value t_out is a float
stored in normal process-local memory. Assigning it directly to
next_gc would create an illegal pointer from shared
memory to local memory (resulting in a crash). By using the
"write protocol" as shown here, the float is copied to shared
memory before doing the assignment.
The solution is surprisingly short. It was never so simple to profit
from shared memory in Ocaml programs. The reason is that we need not
to deal with serialization formats to translate values to strings. We
just store values directly! It should also be noted that there are
additional dangers resulting from shared memory. The worker processes
are no longer completely isolated from each other - we made an
exception by sharing memory for the cache. If a worker fails to comply
to all programming rules required for accessing shared memory, not
only this worker will crash, but all workers. Another risk are the
shared locks. Imagine what happens when a worker is terminated in the
middle of the cache_store function (e.g. by sending
a signal from outside). The lock will never be released again, and
the other workers will wait forever for the lock.
Anyway, these risks are manageable, and are roughly equivalent in
severity to what multi-threaded programming is also exposed to. In
summary, Netmulticore solves some of the problems arising from using
multi-processing, and is definitely worth considering it.





