Last week I spent some time running map/reduce jobs on Amazon EC2.
In particular, I compared the performance of Plasma, my own map/reduce
implementation, with Hadoop. I just wanted to know how much my implementation
was behind the most popular map/reduce framework. However, the suprise was
that Plasma turned out as slightly faster in this setup.
I would not call this test a "benchmark". Amazon EC2 is not a
controlled environment, as you always only get partial machines, and
you don't know how much resources are consumed by other users on the
same machines. Also, you cannot be sure how far the nodes are off
from each other in the network. Finally, there are some special
effects coming from the virtualization technology, especially the
first write of a disk block is slower (roughly half the normal speed)
than following writes. However, EC2 is good enough to get an
impression of the speed, and one can hope that all the test runs
get the same handicap on average.
The task was to sort 100G of data, given in 10 files. Each line has
100 bytes, divided into a key of 8 bytes, a TAB character, 90 random
bytes as value, and an LF character. The key was randomly chosen from
65536 possible values. This means that there were lots of lines with
the same key - a scenario where I think it is more typical of map/reduce
than having unique keys. The output is partitioned into 80 sets.
I allocated 1 larger node (m1-xlarge) with 4 virtual cores and 15G of
RAM acting as combined name- and datanode, and 9 smaller nodes
(m1-large) with 2 virtual cores and 7.5G of RAM for the other
datanodes. Each node had access to two virtual disks that were
configured as RAID-0 array. The speed for sequential reading or
writing was around 160 MB/s for the array (but only 80 MB/s for the
first time blocks were written). Apparently, the nodes had Gigabit
network cards (the maximum transfer speed was around 119MB/s).
During the tests, I monitored the system activity with the sar utility.
I observed significant cycle stealing (meaning that a virtual core is
blocked because there is no free real core), often reaching values of
25%. This could be interpreted as overdriving the available resources,
but another explanation is that the hypervisor needed this time for
itself. Anyway, this effect also questions the reliability of this
test.
The contrahents
Hadoop is the top dog in the map/reduce scene. In this test, the
version from Cloudera 0.20.2-cdh3u2 was used, which contains more than
1000 patches against the vanilla 0.20.2 version. Written in Java, it
needs a JVM at runtime, which was here IcedTea 1.9.10 distributing
OpenJDK 1.6.0_20. I did not do any tuning, hoping that the configuration
would be ok for a small job. The HDFS block size was 64M, without
replication.
The contender is Plasma Map/Reduce. I started this project two years
ago in my spare time. It is not a clone of the Hadoop architecture,
but includes many new ideas. In particular, a lot of work went into
the distributed filesystem PlasmaFS which features an almost complete
set of file operations, and controls the disk layout directly. The
map/reduce algorithm uses a slightly different scheme which tries
to delay the partitioning of the data to get larger intermediate files.
Plasma is implemented in OCaml, which isn't VM-based but compiles
the code directly to assembly language. In this test, the blocksize
was 1M (Plasma is designed for smaller-sized blocks). The software
version of Plasma is roughly 0.6 (a few svn revisions before the release
of 0.6).
Results
The runtimes:
| Hadoop: | 2265 seconds (37 min, 45 s) |
| Plasma: | 1975 seconds (32 min. 55 s) |
Given the uncertainty of the environment, this is no big difference.
But let's have a closer look at the system activity to get an idea
why Plasma is a bit faster.
CPU
In the following I took simply one of the datanodes, and created
diagrams (with kSar):
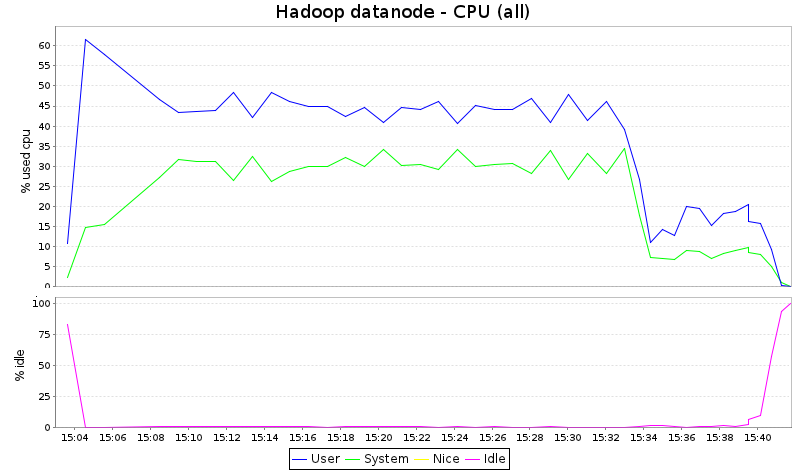
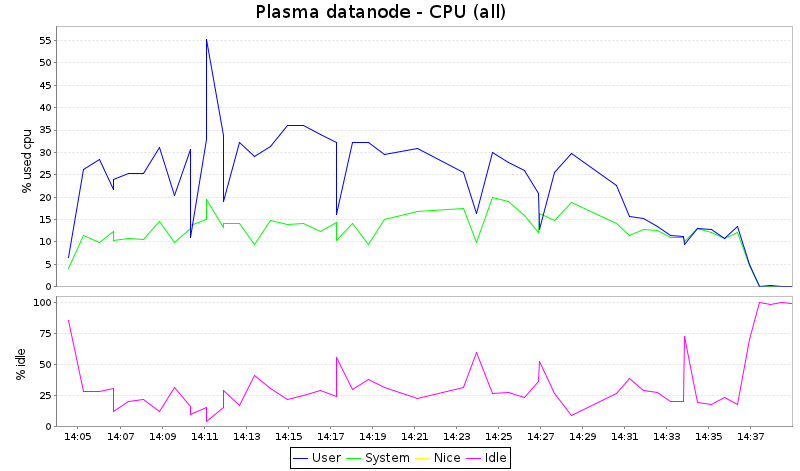
Note that kSar does not draw graphs for %iowait and %steal, although
these data are recorded by sar. This is the explanation why the sum of
user, system and idle is not 100%.
What we see here is that Hadoop consumes all CPU cycles, whereas
Plasma leaves around 1/3 of the CPU capacity unused. Given the fact
that this kind of job is normally I/O-bound, it just means that Hadoop
is more CPU-hungry, and would have benefit from getting more cores
in this test.
Network
In this diagram, reads are blue and red, whereas writes are green and
black. The first curve shows packets per second, and the second bytes
per second:
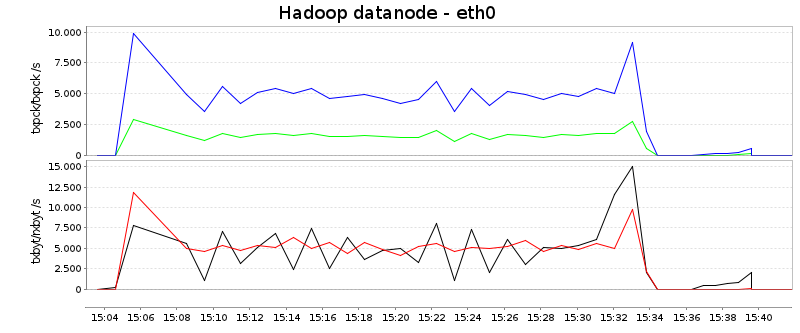
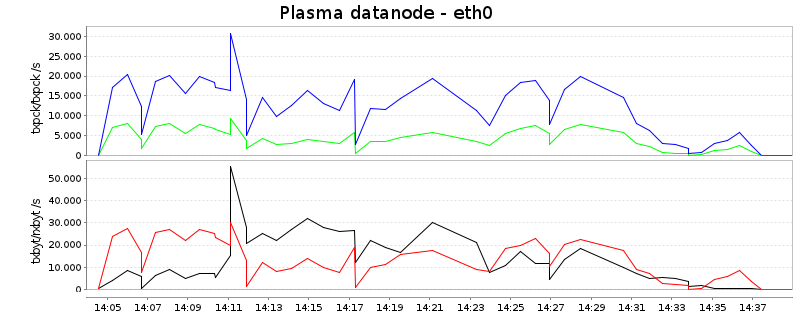 Summing reads and writes up, Hadoop uses only around 7MB/s on average
whereas Plasma transmits around 25MB/s, more than three times as
much. There could be two explanations:
Summing reads and writes up, Hadoop uses only around 7MB/s on average
whereas Plasma transmits around 25MB/s, more than three times as
much. There could be two explanations:
- Because Hadoop is CPU-underpowered, it remains below its
possibilities
- The Hadoop scheme is more optimized for keeping the network
bandwidth as low as possible
The background for the second point is the following: Because Hadoop
partitions the data immediately after mapping and sorting, the data
has (ideally) only to cross the network once. This is different in
Plasma - which generally partitions the data iteratively. In this
setup, after mapping and sorting only 4 partitions are created, which
are further refined in the following split-and-merge rounds. As we
have here 80 partitions in total, there is at least one further step
in which data partitioning is refined, meaning that the data has to
cross the network roughly twice. This already explains 2/3 of the
observed difference. (As a side note, one can configure how many
partitions are initially created after mapping and sorting, and it
would have been possible to mimick Hadoop's scheme by setting this
value to 80.)
Disks
These diagrams depict the disk reads and writes in KB/second:
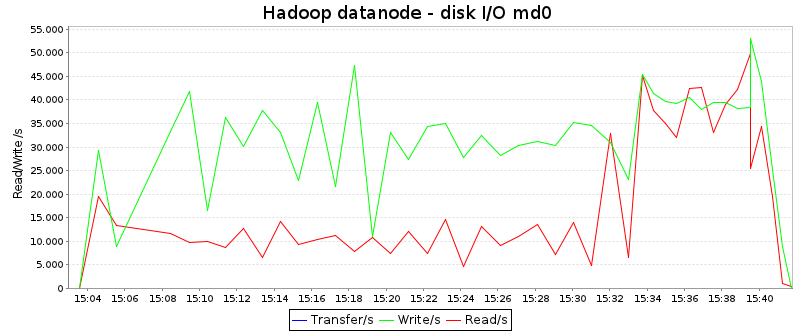
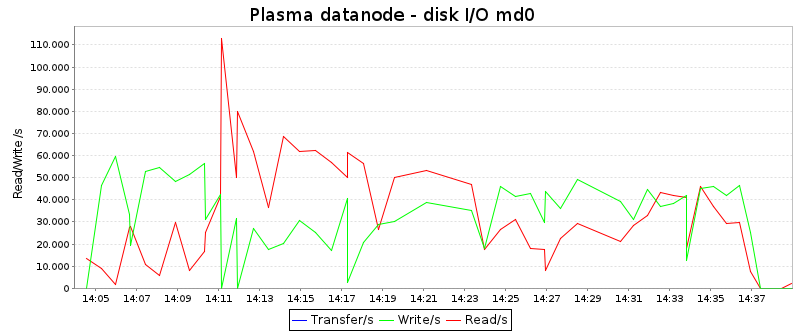 The average numbers are (directly taken from sar):
The average numbers are (directly taken from sar):
| |
Hadoop |
Plasma |
| Read/s: |
17.6 MB/s |
31.2 MB/s |
| Write/s: |
30.8 MB/s |
33.9 MB/s |
Obviously, Plasma reads data around twice as often from disk than
Hadoop, whereas the write speed is about the same. Apart from this, it
is interesting that the shape of the curves are quite different:
Hadoop has a period of high disk activity at the end of the job (when
it is busy merging data), whereas Plasma utilizes the disks better
during the first third of the job.
Plausibility
Neither of the contenders utilized the I/O resources at all times
best. Part of the difficulty of developing a map/reduce scheme is to
achieve that the load put onto the disks and onto the network is
balanced. It is not good when e,g, the disks are used to 100% at a
certain point and the network is underutilized, but during the next
period the network is at 100% and the disk not fully used. A balanced
distribution of the load reaches higher throughput in total.
Let's analyze the Plasma scheme a bit more in detail. The data set of
100G (which does not change in volume during the processing) is copied
four times in total: once in the map-and-sort phase, and three times
in the reduce phase (for this volume Plasma needs three merging
rounds). This means we have to transfer 4 * 100G of data in total, or
40G of data per node (remember we have 10 nodes). We ran 22 cores for
1975 seconds, which gives a capacity of 43450 CPU seconds. Plasma
tells us in its reports that it used 3822 CPU seconds for in-RAM
sorting, which we should subtract for analyzing the I/O
throughput. Per core these are 173 seconds. This means each node had
1975-173 = 1802 seconds for handling the 40G of data. This makes
around 22 MB per second on each node.
The Hadoop scheme differs mostly in that the data is only copied twice
in the merge phase (because Hadoop by default merges more files in
one round than Plasma). However, because of its design there is an
extra copy at the end of the reduce phase (from disk to HDFS). This
means Hadoop also solves the same job by transferring 4 * 100G of data.
There is no counter for measuring the time spent for in-RAM sorting.
Let's assume this time is also around 3800 seconds. This means each
node had 2265 - 175 = 2090 seconds for handling 40G of data, or
19 MB per second on each node.
Conclusion
It looks very much as if both implementations are slowed down by
specifics of the EC2 environment. Especially the disk I/O, probably
the essential bottleneck here, is far below what one can expect.
Plasma probably won because it uses the CPU more efficiently, whereas
other aspects like network utilization are better handled by Hadoop.
For my project this result just means that it is on the right track.
Especially, this small setup (only 10 nodes) is easily handled, giving
prospect that Plasma is scalable at least to a small multitude of
this. The bottleneck would be here the namenode, but there is still a
lot of headroom.
Where to get Plasma
Plasma Map/Reduce and PlasmaFS are bundled together in one download. Here is the
project page.






 Summing reads and writes up, Hadoop uses only around 7MB/s on average
whereas Plasma transmits around 25MB/s, more than three times as
much. There could be two explanations:
Summing reads and writes up, Hadoop uses only around 7MB/s on average
whereas Plasma transmits around 25MB/s, more than three times as
much. There could be two explanations:

 The average numbers are (directly taken from sar):
The average numbers are (directly taken from sar):
