What's new in Ocamlnet 3: Highly-available RPC
- by Gerd Stolpmann,
2009-11-04
Ocamlnet is being renovated, and there will be soon a first testing
version of Ocamlnet 3. The author, Gerd Stolpmann, explains in a
series of articles what is new, and why Ocamlnet is the best
networking platform ever seen. Experience with Hydro, another RPC
implementation for Ocaml using the ICE protocol, has shown that it is
advantageous to provide a layer that automatically manages the reaction
of the RPC system in case of machine failures. Ocamlnet 3 adds
such a layer for SunRPC clients.
The SunRPC client implementation included in past versions of Ocamlnet
does not deal in any way with connection failures. The socket error
was simply passed through to the caller, and the RPC client had then
to be shut down. It was up to the caller how to react on such
incidents. For example, one could indicate to the end user that the
operation cannot be carried out, or one could retry the
call. Programming practice showed that it is cumbersome to develop
anew the right reaction for every type of RPC connection used in a
larger system. The upcoming Ocamlnet 3 release tries to be better
here. On top of the existing Rpc_client module the
programmer may now install an Rpc_proxy module that
handles socket errors much more nicely.
However, before going into detail here, let us first step back, and
look at distributed systems that try to handle machine failures. The
assumption here is that a socket error is caused by a malfunctioning
(usually dead) machine, and that a simple repetition of the RPC call
to the same machine is not the most prospective reaction. Distributed
systems that can cope with failures of one or several nodes are called
highly available (HA). The development of software that has
built-in HA capabilities is known be very difficult, and it is
especially useful when there is library support for dealing with
machine failures.
Examples of fail-over scenarios
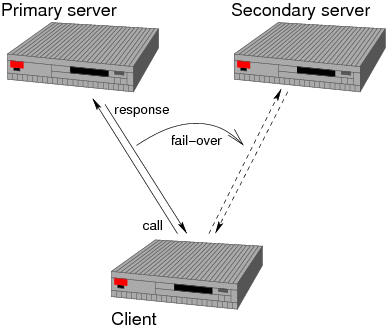
A frequent case is the simple fail-over from one server to an
alternate server (see picture). Ideally, the alternate server is a
copy of the primary server and operates on exactly the same data set.
It is beyond the scope of this article how this can be achieved
- possible solutions include hardware-based approaches like switching
disks from one machine to the other, or software approaches like
replicating all data modifications by means of commit protocols.
For Ocamlnet it is only important that the client needs a criterion
for when to switch to the other server, and instructions how to
switch.
When to switch: Basically, we have the case that the client can
autonomously decide whether to contact the secondary server instead of
the primary one, and the case that the client needs external help.
For example, the client could look at socket errors, and if the number
of such errors for a certain server exceeds a maximum, the server is
declared to be dead, and the client switches autonomously to the
alternate server. This is convenient, but it assumes that the
alternate server is at any time a replacement for the primary one.
Especially when the fail-over is hardware-based this is not valid -
before the alternate server is ready a special fail-over procedure
must be run that disconnects the disks from the old server and
attaches them to the replacement machine. Also, the old server needs
to be isolated (i.e. "zombie machines" are ensured to be unreachable
from the rest of the network). There is another reason for relying on
external information about when to switch: Often, it is resaonable to
monitor the cluster machines by special monitoring daemons. These are
in a better position to collect and aggregate information about the
liveliness of the cluster machines. For example, such services can
contiuously ping the nodes of the cluster and also check which network
ports are actually reachable. So it is often advisable to factor out
the decision whether a node is alive or dead even if the client could
do this on its own.
How to switch: RPC calls that can be simply repeated without
changing the meaning are called idempotent. For example, if the client
just wants to get the value of a remote variable, the RPC call doing
so can be simply repeated as often as necessary to obtain the result.
In contrast to that an RPC procedure that modifies a remote variable
can often not be repeated (e.g. imagine an integer variable is
increased by 1). This case is way more complicated to handle, and one
ends often up with a so-called commit protocol. This means that the
modification is encapsulated as a transaction that is either
completely executed or aborted meaning that the effects are completely
nullified. The commit protocol ensures that both the client and the
server know whether the transaction is finally done or not done. Also,
the commit protcol makes it possible to keep data sets synchronized
that are stored on several servers. For Ocamlnet this means that the
right reaction is either trivial (redirection of the failed idempotent
call to the alternate server), or so complex that generic library
support is impossible.
A HA scheme for partitioning data
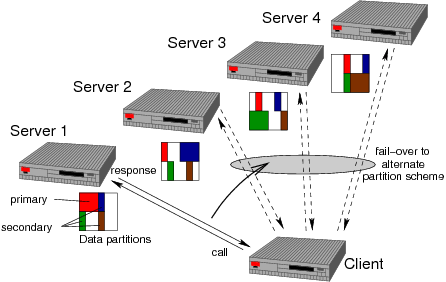 Often, HA is not the only reason for using a cluster of computers.
Another motivation is to increase the total capacity of the system by
spreading the load over several systems. In the picture there is an
example where the load is shared by four servers. For pure
load-balancing there is no need to check for and manage connection
failures - before doing an RPC call, the right destination machine is
simply selected, and the call is directed to it.
Often, HA is not the only reason for using a cluster of computers.
Another motivation is to increase the total capacity of the system by
spreading the load over several systems. In the picture there is an
example where the load is shared by four servers. For pure
load-balancing there is no need to check for and manage connection
failures - before doing an RPC call, the right destination machine is
simply selected, and the call is directed to it.
However, load-balancing can be combined with HA. The depicted
system allows the client to read-access a dataset that is split into
four partitions - the read, blue, gree, and brown partition. Each
server has one of these partitions as its primary dataset. For
example, when the client needs to read a data item from the blue
partition it can go to server 2 because this server has all "blue
data" (shown as blue square). In addition to that, all servers also
store replicated data from other servers to provide a back-up in the
case that a node fails. An easy way to do this would be to store the
replica for server k on server k'=(k+1) mod N. However, this leads to
the problem that the server k' gets double load when server k fails,
foiling the increase of capacity by sharing load. The system in the
picture implements a better scheme. Here, the partitions are further
subdivided so that equal fractions of any partition are replicated on
all machines. For example, the blue partition is split into three
smaller parts which are then replicated on the three alternate
nodes. When server 2 fails, the client can still find all the "blue
data" on the remaining three machines, and because all remaining
machines get an equal part of the fail-over load the overall capacity
of the system shrinks only by 25%.
This scheme has to be considered for the Ocamlnet library in so far
it is no longer always the same node that replaces a failing node. It
depends now on the data item which server is the right alternate
machine if the primary server fails.
Detecting node outages
When a node goes down, we assume that any pending TCP connection to it
hangs, and also that attempts for creating new connections are not
responded. After some time, the router usually detects that the node
is unavailable, and emits special ICMP packets notifying machines in
the network about the outage. However, this takes usually a few
minutes. Until then, the cluster system needs other mechanims to
detect the unavailablility of the node.
In the literature (including this text) a machine is usually either
up or down, and there is nothing in between. In practice, however, the
problem of zombie machines really exists, and is not as rare as many
think. Often, the cause for hovering between life and death are bad
disks - disk accesses still work, but take a multitude of the usual
time to complete. Of course, such bad nodes are unusable, and should
be counted to the dead nodes, but the problem is that the network
ports are still responsive. This does not render the network
connectivity tests useless, but one should keep in mind that these
tests do not cover all reasons for an outage.
The most basic mechanism for recognizing failed nodes are timeouts.
Due to the nature of timeouts it takes some time until such a test can
indicate a failure, and this limits the usefulness of timeouts.
Nevertheless, timeouts are important even when there are better
criteria because they are often the only way to interrupt already
established but now hanging TCP connections. We have to distinguish
between two kinds of timeouts: Firstly, there are timeouts on
individual send and receive operations. In many implementations of
network protocols these are the only kind of timeouts. Essentially,
these timeouts specify a lower bound on the bandwidth of the
connection, and they work independently of the length of the exchanged
messages. Secondly, one can also set an upper bound on the total time
for the RPC call (including the time for both the request and the
response). As RPC is usually run on fast LAN's, and specifications of
RPC systems often require upper limits on the latency as seen by the
end user (something like "95% of the user requests must be responded
within 0.5 seconds"), this second interpretation is the more
interesting one. Actually, Ocamlnet only implements this second notion
of timeout.
The question is whether there are faster ways of detecting failed
nodes. One method is surprisingly simple: Each node running an RPC
client pings the nodes with the RPC servers the clients are connected
to. A repeatedly failed ping is considered as a node outage. Ocamlnet
3 does not (yet) implement such a component, but the new
Rpc_proxy layer is prepared to take external
information about outages into account. (For an implementation look at
Hydromon. Although
written for ICE instead of SunRPC it is straight-forward to port
Hydromon to Ocamlnet's SunRPC implementation.) Even on busy servers
this method is able to detect bad nodes within a few seconds.
Another idea is to share information about good and bad nodes as
much as possible. If one connection runs into a timeout and the node
is considered as failed, this information should be made available
to all threads, and if possible even to all processes of the node.
This avoids further attempts to connect to the failed node, and one
can even cancel pending calls to this node.
Proxies: Configurable connection management
After this lengthy foreword, let's look at the actual implementation
of connection management in
Rpc_proxy. The name, "proxy",
reminds us of the ideal of RPC: A remote call should be as simple and
safe to conduct as a local procedure call, and the "proxy" is the
local agent dealing with most of the complexities of remote calls,
so that they look as much as possible like local calls.
This module is divided into three parts:
Rpc_proxy.ReliabilityCache remembers which nodes
and which network ports failed in the past, and decides on this
information which nodes are considered to be down.
Rpc_proxy.ManagedClient is an encapsulation of
the simpler Rpc_client that is able to reconnect to a
service. Effectively, a ManagedClient is a single TCP
connection to a remote service that can be reestablished after an
error.
Rpc_proxy.ManagedSet is a set of
ManagedClients for the same RPC service that controls how
many RPC calls are
routed over each managed client, and that also implements the logic
for skipping bad clients.
The generator for the language mapping, ocamlrpcgen,
has also been extended. It emits now a functorized version of the
client wrappers. For example, for the RPC program P the
generator would output a functor
module Make'P : Rpc_client.USE_CLIENT -> sig ... end
where the returned module includes for every procedure
p
a call wrapper
val p : C.t -> argument -> result
Here,
C is the input module
Rpc_client.USE_CLIENT. This means one can inject any
client implementation that at least implements
Rpc_client.USE_CLIENT, and is not restricted to the
default implementation
Rpc_client. Of course, the
enhanced client implementation
Rpc_proxy also provides
the
Rpc_client.USE_CLIENT functionality, so it can be
substituted here:
module P = Make'P(Rpc_proxy.ManagedClient)
The user is free, however, to pass any module as input here that meets
the formal requirements - for example, one could pass further improved
or derived versions of
Rpc_proxy.ManagedClient. (Of
course, the output generated by the new
ocamlrpcgen is
compatible with what earlier versions emitted. For users it is not
required to switch to the functorized version.)
Comparing basic clients and managed clients
Basic clients as provided by
Rpc_client live as long as the
underlying TCP connection exists. This means the connection is created
at the beginning of the client's lifetime, and the client becomes
unsuable when the connection ends (either programmatically, or because
of socket errors). In contrast to this, a managed client can establish
the connection again when needed - but only to the same host and port.
(Fail-overs to other hosts/ports are implemented in
ManagedSet,
see below.)
The basic clients are configured after being created - by invoking
configuration functions like configure,
set_exception_handler or set_auth_methods.
This has the advantage that the configuration can be changed during the
lifetime of the client. For managed clients, however, we require that the
configuration must be fully given at creation time. The point is here
that the managed client internally creates a series of basic clients,
and immediately needs to know how these clients are to be configured.
For example, this piece of code creates a managed client:
let mconfig =
Rpc_proxy.ManagedClient.create_mclient_config
~programs:[ P._program ]
~msg_timeout: 10.0
()
let mclient =
Rpc_proxy.ManagedClient.create_mclient
(Rpc_client.Internet(Unix.inet_addr_of_string "10.3.2.55", 9005))
(esys : Unixqueue.event_system)
Note that the TCP connection is not immediately created, but only
when the first remote procedure is called. This is on line with the
automatic reconnection feature: When the connection is closed or
crashes, the next procedure call triggers that the connection is
established again.
In this example, we have only configured a message timeout - the
client will signal a timeout when the response takes more than 10
seconds to arrive. Normally, the timeout does not mean that the
connection is considered as broken. We have to explicitly configure
this feature - the proxy layer cannot know by itself what possible
reasons for timeouts are. This is just another argument of
create_mclient_config:
Rpc_proxy.ManagedClient.create_mclient_config
... ~msg_timeout_is_fatal:true ... ()
A fatal error is recorded, and may, depending on the configuration
of the ReliabilityCache, disable the server host and/or
server port for some time. The ManagedSet layer will
recognize the error situation, and take this information into account
when selecting good server endpoints for future RPC calls - but more
on that below. On the level of ManagedClient it is only
important to define which malfunctions are considered as fatal errors
that may trigger the fail-over to other server nodes. As a
ManagedClient is always only connected with one server
node it is pointless to decide what to do in case of node failures.
There are two more connection management features:
- One can set an idle timeout. Unused TCP connections are closed
after the idle timeout period is over. The idea is to save
server resources by closing unused connections - which often also
means that the thread or process in the server can be released.
Also, some network configurations do not tolerate that connections
remain unused for longer periods of time.
- One can demand to ping the service before sending the first
RPC request. The background is that servers usually accept TCP
connections before knowing whether there are really enough resources
to handle them (i.e. free threads or processes). So it may happen
that a TCP connection can be established, but it turns out to be
immediately dead. By requesting one ping before really using the
connection one can detect this problem.
Once the ManagedClient is configured and created, it
can be used in a similar way as the older Rpc_client. For
example, to call do_something we would write
let result = P.do_something mclient argument
(given that
P is the applied functor from above). The
asynchronous version,
P.do_something'async is also
available.
The ReliabilityCache
The reliability cache is the instance that decides whether a server
host or server port is available or not. The cache implements a logic
for disabling servers when RPC clients recently reported fatal errors.
Higher RPC levels such as
ManagedSet can then interpret
this information and fail-over to alternate servers. In the bigger
picture outlined in the first half of this article the cache plays
primarily the role of the autonomous fail-over trigger. In addition to
that, there is also a hook for plugging in external sources for
recognizing dead nodes.
The reliability cache is notified by the managed clients whether
RPC calls lead to fatal errors or not. The cache disables the host or
port of the server when a certain number of fatal errors occur in
sequence. As we don't have a better idea for how long to disable, the
cache simply implements a time-based logic where the length of the
time period the server is assumed to be down depends on the number of
fatal errors: Following fatal errors double the duration of the
assumed unavailability until a maximum duration is reached. (A
justification for this logic are server overloads: When a server
cannot be contacted because of too much load, it is reasonable to
delay the addition of load, and to consider the delay as a function of
past slowness.)
There is usually only one reliability cache per process (the
"global" cache). This is reasonable because the information about
failures should be spread as far as possible. Nevertheless, each
ManagedClient can configure its own criteria when to
disable servers. The function
val derive_rcache : rcache -> rcache_config -> rcache
makes this possible: A new cache is created with a new configuration,
but the cache shares error data with a parent cache. For example, this
could be used to set the hook for getting external liveliness
information:
let rconfig =
Rpc_proxy.ReliabilityCache.create_rcache_config
~availability:(fun rcache sockaddr -> ...)
()
let rc =
Rpc_proxy.ReliabilityCache.derive_rcache
(Rpc_proxy.ReliabilityCache.global_rcache())
rconfig
Right now, there is no mechanism to make the mentioned error
counters accessible across process boundaries. This may be added in
future versions of Ocamlnet.
The ManagedSet of RPC clients
Finally, we come to the layer that represents possible connections to
several server nodes, and that decides what to do when one of the
servers dies.
A managed set of clients is configured by specifying an array of
remote addresses (usually corresponding to the available server
nodes). For each of the addresses the set may create a managed
client. Basically, there are two scenarios: Either the addresses are
seen as alternate server endpoints (when the first one fails try the
second etc.), or they are seen as equivalent, and it is tried to
distribute the load over all server endpoints that are alive. This
translates into the two policies managed sets can operate under:
`Failover and `Balance_load.
For example, this managed set specifies a fail-over policy:
When 10.3.2.55 fails, it tries to contact 10.3.3.55 instead.
let sconfig =
Rpc_proxy.ManagedSet.create_mset_config
~policy:`Failover
()
let mset =
Rpc_proxy.ManagedSet.create_mset
sconfig
[| Rpc_client.Inet(Unix.inet_addr_of_string "10.3.2.55", 9009), 100;
Rpc_client.Inet(Unix.inet_addr_of_string "10.3.3.55", 9009), 100;
|]
(esys : Unixqueue.event_system)
The number 100 is the maximum number of simultaneous connections to
this endpoint. The managed set automatically increases the number of
connections to the selected endpoint when the load grows (where the
load is the number of simultaneously submitted RPC calls - remember
this is an asynchronous RPC implementation, and it is able to handle
several RPC calls at the same time). When the maximum is reached,
further connections attempts are not rejected, but the alternate
endpoint is then used instead. (So `Failover does not
prevent that the alternate endpoint is used, it only specifies the
preference to use the first endpoint as long as possible.)
If we had passed ~policy:`Balance_load instead, the
managed set would create connections to both servers, and try to
achieve that the number RPC calls directed to each of the servers is
roughly the same.
The user code calls mset_pick to get the next managed
client according to these selection rules:
let mclient, index =
Rpc_proxy.ManagedSet.mset_pick mset
There is also the optional
from argument allowing to
restrict the endpoints from which the client must be chosen. E.g.
let mclient, index =
Rpc_proxy.ManagedSet.mset_pick ~from:[2;3] mset
would take either the endpoint at index 2 or the endpoint at index 3
from the endpoint array, and return the actually selected index. This
is useful for fail-over scenarios where the node is a function of the
input data - like in the presented partitioning example.
Managed sets do not repeat failed RPC calls by themselves. They
only record failures in the rcache, and if enough
failures happened, the problematic server is no longer considered as
alive when submitting new calls. For idempotent calls, however, there
is some support for automatic repetition. But first let's have a
closer look at how the clever partitioning scheme from the above
picture could be implemented.
Sketch how to implement partitioned data sets
In this example, we had four servers:
let server1 =
Rpc_client.Inet(Unix.inet_addr_of_string "10.0.0.1", 7654)
let server2 =
Rpc_client.Inet(Unix.inet_addr_of_string "10.0.0.2", 7654)
let server3 =
Rpc_client.Inet(Unix.inet_addr_of_string "10.0.0.3", 7654)
let server4 =
Rpc_client.Inet(Unix.inet_addr_of_string "10.0.0.4", 7654)
In order to access the data item with key
k : key we define
two hash functions, one for the primary partitioning scheme, and
one for the secondary scheme:
val h_primary : key -> int (* actually: key -> {0..3} *)
val h_secondary : key -> int (* actually: key -> {0..3} *)
For example, one could define these as:
let h_primary (k : string) =
(Char.code (Digest.string k).[0]) land 3
let h_secondary (k : string) =
let h1 = h_primary k in
let rec attempt j =
let k' = k ^ string_of_int j in
let h2 = (Char.code (Digest.string k').[0]) land 3 in
if h2 = h1 then (
if j = 4 then
(h1+1) mod 4 (* ensure that the loop terminates *)
else
attempt (j+1)
) else
h2
in
attempt 0
Now, we create our managed set:
let sconfig =
Rpc_proxy.ManagedSet.create_mset_config
~policy:`Failover
()
let mset =
Rpc_proxy.ManagedSet.create_mset
sconfig
[| server1, 100;
server2, 100;
server3, 100;
server4, 100;
|]
(esys : Unixqueue.event_system)
When trying to get the record for key
k, we first compute
the two nodes that store this record:
let n1 = h_primary k
let n2 = h_secondary k
Finally, we pick a managed client from the managed set. We have to restrict
the set of available servers to those where the paritioning functions say
they store the record. So we get
let mclient, index =
Rpc_proxy.ManagedSet.mset_pick ~from:[n1;n2] mset
The mclient can then be used for calling a remote
procedure. Remember that managed clients/sets do not automatically
repeat failed calls, so we still can get socket errors etc. The error
is only recorded, and when the server looks too faulty, it is finally
disabled, and the managed set will no longer pick it. Such a call
could look like:
let result = P.get_file mclient file_id
Idempotent calls can be repeated without changing the semantics.
For this reason, managed sets have a little helper to do so:
let result =
Rpc_proxy.ManagedSet.idempotent_sync_call
~from:[n1;n2]
mset
P.get_file'async
file_id
This would repeat the get_file call in case of
errors (up to a configurable maximum). Note that we have to pass
the asynchronous version of get_file as argument although
the resulting call is synchronous.
Summarized, the proxy module achieves that the actual fail-over
logic is implemented within ManagedSet and the layers
below it. The user code can rather focus, as shown, on describing
which server to chose, and does not need to think in actions ("if this
fails then try that").
Where to get Ocamlnet 3
There is no official release yet, not even an alpha release for
developers. In order to get it, one has to check out
the Subversion repository (use the svn command
on this URL, or click on it to view it with your web browser - most
of the discussed code lives in src/rpc).


 A frequent case is the simple fail-over from one server to an
alternate server (see picture). Ideally, the alternate server is a
copy of the primary server and operates on exactly the same data set.
It is beyond the scope of this article how this can be achieved
- possible solutions include hardware-based approaches like switching
disks from one machine to the other, or software approaches like
replicating all data modifications by means of commit protocols.
For Ocamlnet it is only important that the client needs a criterion
for when to switch to the other server, and instructions how to
switch.
A frequent case is the simple fail-over from one server to an
alternate server (see picture). Ideally, the alternate server is a
copy of the primary server and operates on exactly the same data set.
It is beyond the scope of this article how this can be achieved
- possible solutions include hardware-based approaches like switching
disks from one machine to the other, or software approaches like
replicating all data modifications by means of commit protocols.
For Ocamlnet it is only important that the client needs a criterion
for when to switch to the other server, and instructions how to
switch.
 Often, HA is not the only reason for using a cluster of computers.
Another motivation is to increase the total capacity of the system by
spreading the load over several systems. In the picture there is an
example where the load is shared by four servers. For pure
load-balancing there is no need to check for and manage connection
failures - before doing an RPC call, the right destination machine is
simply selected, and the call is directed to it.
Often, HA is not the only reason for using a cluster of computers.
Another motivation is to increase the total capacity of the system by
spreading the load over several systems. In the picture there is an
example where the load is shared by four servers. For pure
load-balancing there is no need to check for and manage connection
failures - before doing an RPC call, the right destination machine is
simply selected, and the call is directed to it.
